There are a a whole bunch of different tools and metrics to evaluate data science model performance. Some of the most common tools and metrics include:
- Confusion Matrix
- Accuracy
- Precision
- Recall
- F1 Score
Honestly, I often forget the definitions for these metrics. I’d like to think it’s partly because the definitions of these tend to be super technical, verbose, and obscure. Not easy for casual reading.
Here I’ll explain these metrics in my own words, which tend to be simple.
What is a model? #
First off, I think it’s worth defining what a “model” is.
A model is a thing that comes out of looking at collected data that includes details on some set of attributes associated with some sort of outcome.
That model is trained on that collected data, so that it can identify patterns. Later on, when that model sees some set combination of attributes again, it’ll try to guess at what the outcome is based on patterns it previously saw.
Let’s use an example. Imagine that the context we’re looking at is whether or not someone snores when sleeping or not (a silly example, but hey, why not?). That’s the outcome. Or in slightly technical terms, that’s the dependent variable.
We also have details on age, gender, whether or not that person has kids, details on diet, and so on. These are the attributes, or independent variables.
The model tries to figure out what the relationship between the combination of independent variables and dependent variable are so that it can guess at what the dependent variable is for another person.
So if say a new person named Bob shows up, and we have details about Bob’s age, gender, kids, diet, etc., the model can feed in that information and try to guess if Bob snores or not.
In this example, because we’re trying to guess at one of two possible outcomes – whether the person snores or not – we can call this a binary classifier.
Model evaluation #
Model evaluation is the process of figuring out how well the model performs at guessing something. Is it wrong a lot? Is it right a lot? What sorts of guesses does it get right or wrong?
This evaluation is usually handled with a test dataset. What we do is is we take some proportion of the total data, set it aside so it never gets involved with the model training and then we pass that data through the model once we’ve trained it.
We have the known outcomes of that data that’s been set aside. We take the independent variables from that test dataset, and feed it through the model. The model should then spit out a bunch of guesses for the dependent variable.
We can then compare the guesses against the known dependent variable values. Depending on how the actual outcomes and the guessed outcomes match up, we can come up with all sorts of measures of model performance.
So for instance, let’s say we know another person Charlie that doesn’t snore. We pass Charlie’s details through the model. The outcome might be a guess that Charlie doesn’t snore, in which case the model was right, or a guess that Charlie does snore, in which case the model would be wrong.
Accuracy #
Accuracy is a simple and common measure for whether or not predictions were correct compared to known outcomes.
Oftentimes though, it’s not sufficient.
Let’s say we know that 90% of the population does not snore. We could easily nail 90% accuracy on average without a model by simply saying everyone does not snore. Full stop. We’ll get it wrong 10% of the time.
But that kind of defeats the purpose. We want something that lets us make better guesses.
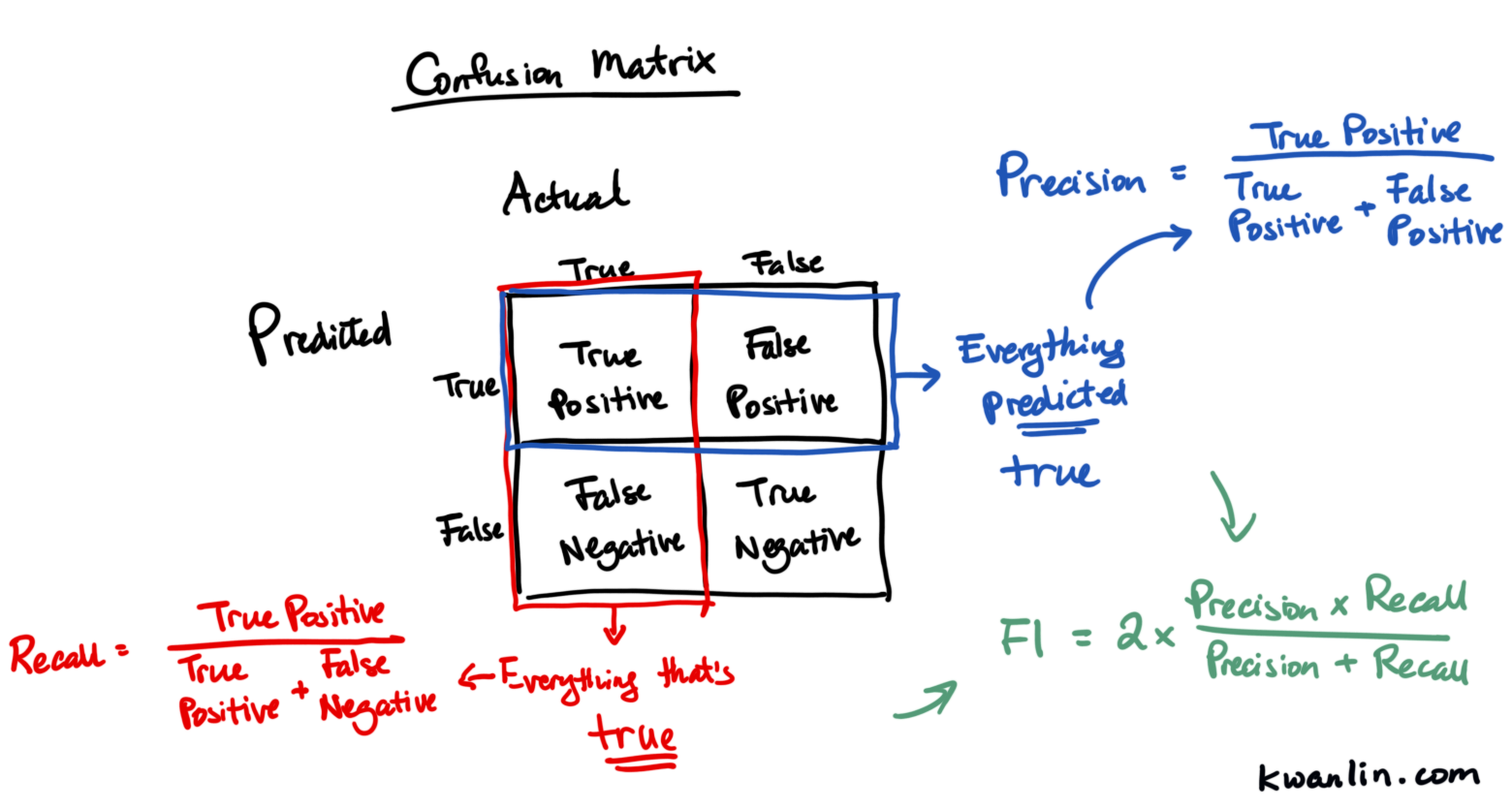
Confusion Matrix #
A confusion matrix is a way to compare known outcomes and guessed outcomes.
If it’s a binary classifier where there are two possible guesses (True/False, Yes/No, etc.), then the matrix ends up looking like a 2x2 grid. One axis represents the true outcome, and another axis represents the guessed or predicted outcome.
The combinations include:
-
True Positive - the things that are true, that were predicted true
-
True Negative - false, predicted false
-
False Positive - actually false, but predicted true
-
False Negative - actually true, predicted false
Usually each box of the confusion matrix gets a count, percentage, or proportion reflecting the outcomes of the different predictions from the model.
Precision #
Precision is the ratio of the true positives over the sum of the true positive and false positive.
You can think of this as of all the things predicted to be true, how many were actually true?
It’s a way of assessing how reliable the true guesses are.
Recall #
Recall is the ratio of the true positive divided by the sum of the true positive and the false positive, or _everything that is true.
Think of recall as how many of the true cases were actually found?
Recall is especially important where the cost of missing a true case is high. For instance, recall is especially important in disease diagnosis, where failing to catch a disease can have huge negative impacts on a patient.
F1 Score #
This is a unified measure that combines both the precision and recall.
A higher F1 score is generally deemed better.
This is a handy metric to rely on when comparing multiple different models.
Parting Thoughts #
Light, simple, and hopefully easy to digeset. There’s more in the space of model evaluation, but we’ll leave it here for now.